
Aktuell spricht alles und jede1 über künstliche Intelligenz (KI).
Ich auch!
Update: Und jetzt werden sogar schon epische Songs über den DataHero gesungen: http://aka.ms/datahero/song 🦸🎼
Update 2: Wenn die Basics in diesem Artikel adressiert sind, dann empfehle ich die Lektüre der weiterführenden Themen: BYOAI kontrollieren und sicherer Umgang mit Unternehmensdaten und unterschiedlichen KI Systemen.
Vor allem bin ich zurzeit häufig eingeladen über Microsoft 365 Copilot zu reden und generell die Sicht von Microsoft auf KI darzustellen.
Neben den ganzen phantastischen Möglichkeiten und Prozessoptimierungen und modernen Formen des Arbeitens gibt es für mich im Kontext von KI zwei wesentliche Säulen, ohne die KI nicht erfolgreich sein kann:
- Passende Szenarien, die aufzeigen, wie KI zum [Unternehmens-| Eigenen-] Erfolg beitragen kann, ein paar Ideen habe ich im Post Der ROI von ChatGPT und Copilot dargestellt, hier ist aber die Kreativität aller gefragt und natürlich gilt es dabei den eigenen Kosmos mitzuberücksichtigen. Dazu zählt natürlich dann auch das Mitnehmen der Nutzerinnen und dem Gesamtthema Adoption and Change Management.
In diesem Post geht es mir allerdings um - Die passende Data Governance!
Und ich bin nicht allein mit dieser Meinung – hier Julie Sweet CEO of Accenture mit einem kurzen Kommentar zur Ignite 2023:
Das Ganze habe ich für mich natürlich auch in ein Bild gegossen:

Die Säulen auf denen KI-Erfolg basiert: am Fuße die Data Governance, auf dem Sockel die Use Cases
Die Reaktionen sind meist: „ja, klingt einleuchtend!„, aber es bleiben dann doch noch Fragezeichen in den Gesichtern, denn was genau soll denn eigentlich „Data Governance“ sein?
Für mich sind das insbesondere folgende Themen, auf die ich einzeln eingehen werde:
Agenda
1. Rollen- und Rechte- Management
In Kopf in den Sand, AI oder doch delven? habe ich bereits das Dilemma aufgezeigt, dass Rollen- und Rechte-Management nicht neu ist und leider viel zu oft „übersehen“ wird.
Im Zuge der Einführung von KI ist es allerdings unerlässlich diesen Missstand aufzulösen und alles daran zu setzen, dass der Zugriff auf jegliche Form von Daten sinnvoll durch Rechte und Rollen gemanaged wird – streng nach dem Zero Trust Prinzip „use least-priviledged access„.
Es ist zwingende Notwendigkeit, dass hier mit äußerster Sorgfalt vorgegangen wird und von Strategie, Einführung, Umsetzung, Mitarbeiterschulungen bis hin zu einer regelmäßigen Überprüfung vorgegangen wird!
Aber hey, ist ja nichts Neues, hilft auch schon im Pre-AI Zeitalter und ist daher bestimmt schon bei dir vollumfänglich gelöst! 😈
2. Datenspeicherorte
Ist doch klar, wo unsere Daten sind: auf unserem File-Share! Da sind sie am sichersten und überhaupt DSGVO!
Dass das so nicht stimmt, könnt ihr in Was hat das Aktenarchiv im Keller, was mein Fileshare nicht hat? nachlesen!
Dass das spätestens mit KI zum Eklat wird, möchte ich hier kurz skizzieren: Wenn Daten „zu weit“ von den KI-Systemen entfernt sind, dann können diese nicht sinnvoll zugegriffen werden und damit auch nicht bei der Nutzung von KI zum Einsatz kommen.
Was meine ich damit? Daten, die auf einem Fileshare liegen, sind oftmals von der Data Governance unberührt. Heißt: ja, da gab es mal so etwas wie eine Berechtigungsstruktur, aber die ist 20 Jahre alt und seitdem einfach nur gewachsen. Dinge wie Schattenkopien und ein vernünftiger Suchindex hätte es auch mal geben sollen… und den Anschluss an Cloud Dienste – und damit KI – gibt es auch nicht! #digitalisierungftw => Wie Cybersecurity dazu beitragen kann, die digitale Transformation voranzutreiben
Also, KI braucht Daten in der „Nähe“ und in einem möglichst brauchbaren Format (siehe 5.). Das wiederum heißt, dass bei der Nutzung von Cloud KI Systemen die Daten unweigerlich in einem (nahen) Cloudsystem gespeichert werden müssen, weil sie sonst keinen Mehrwert für die KI haben!
Wer es also bis jetzt versäumt hat, Daten sinnvoll in die Microsoft Cloud zu migrieren, der hat jetzt die Chance das schleunigst nachzuholen, weil sonst findet man sich bald auf dem Daten- und damit Business-Abstellgleis!
Die Nutzung von KI stellt heute noch (grade so) einen Wettbewerbsvorteil dar, aber schon sehr bald wird die „Nicht-Nutzung“ zu einem Wettbewerbsnachteil!
Stephanus Schulte
3. Datenkategorien
Ein KI System kann nur so gut sein, wie seine Daten(quellen)!
Stephanus Schulte
Ein KI-System zur Auswertung von Business Ergebnissen braucht zwingend den Zugriff auf den Speiseplan der Kantine, oder!?
Genau! Und deshalb ist es unumgänglich, dass die im Unternehmen vorhandenen Datenkategorien nicht nur erkannt, sondern auch (IT seitig) angewendet werden, damit die unterschiedlichen KI-Systeme an die best-möglichen Daten angeschlossen werden können.
Dazu zählt neben Dingen wie Datenklassifizierung (Dateien, Datenbanken, Datalakes, etc.) auch eine Datamap und mit der Klassifizierung auch eine Strategie zur Verschlüsselung und Data Loss Prevention.
Neu seit Ignite 2024: Microsoft 365 Copilot blueprint for oversharing | Microsoft Learn sowie Simplify & scale data protection in the era of AI with Microsoft Purview Data Loss Prevention | Microsoft Community Hub
Siehe dazu auch das kurzweilige Mechanics Video: Kontrolle über zu viele Freigaben im Unternehmensmaßstab |Microsoft 365 Copilot in Microsoft Purview
4. Datenlebenszyklus
„Haha – jetzt hast du keine Lösung mehr!“ Höre ich oft (und gerne), wenn es um das Thema „KI und das Datenvergessen“ geht!
Denn, anders als es landläufig geglaubt wird, ist es (zumindest bei den KI-Systemen von Microsoft) so, dass die KI-Systeme die eigentlichen „Brauch-Daten“ gar nicht „erlernen“!
(Hinweis zum Thema KI und Datenvergessen: Who’s Harry Potter? Making LLMs forget – Microsoft Research )
Sprich das KI-System saugt nicht einfach so die Daten auf – also der M365 Copilot wird eben nicht mit z.B. der Word Datei, in die ich diesen Blogpost vorschreibe, trainiert!
Hä???
Ja, genau, das ist nämlich mit den aktuellen Systemen auf der Welt nicht zu bezahlen bzw. technisch unmöglich und genau deswegen passiert es auch nicht.
Überlegt mal, wie viel Trainingsvorgänge es geben müsste, bei der Bearbeitung dieses Blogposts als Worddatei in Onedrive! Quasi jeder Buchstabe wird sofort gespeichert und würde jedes Mal einen neuen Trainingsdurchlauf veranlassen – das ist so weder sinnvoll noch machbar! (Auch nicht, wenn man entsprechende Zeiten abwarten würde. Die Anzahl der Änderungen ist einfach zu hoch, um damit klassisches KI-Training durchzuführen!)
Diese Erkenntnis führt dazu, dass das System sicher anders funktioniert. Und genau so ist es. Das Large Language Model wird zum „Verstehen“ und zum Generieren verwendet, um dann etablierte Suchmechanismen zu verwenden, um die richtigen Dokumente – so wie sie z.B. im SharePoint abgelegt sind – zu finden, dann je nach Prompt z.B. zusammenzufassen und dann dem User das Ergebnis zu präsentieren.
Das wiederum bedeutet, dass es sinnvoll ist, die Systeme und insb. den Index frei von Altlasten zu halten.
Zum einen macht „er“ (der Index) das zum Teil selbstständig, zum anderen können wir dies durch sog. Retention(policie)s begünstigen und alte, kalte, unwichtige Daten entsprechend aussortieren.
Das, was ich hier beschrieben habe, entspricht einem Retrieval Augmented Generation (RAG) Prozess.
5. Datenhygiene
Last but definitely not least kommen wir zu meinem Lieblingsthema der Datenhygiene.
Und da möchte ich gleich mit
5.1 Benamung und Ablagesystem
anfangen.
Der geneigte Lesende hat sicher noch meinen Post Was hat das Aktenarchiv im Keller, was mein Fileshare nicht hat? im Kopf, bei dem es um den Vergleich von Papier im Keller zu Daten auf einem Fileshare ging. 😇
Genau das ist jetzt (schon wieder) das Thema! Denn wer sich auch bei der digitalen Datenablage sinnvolle Methoden hat einfallen lassen, bzw. Best-Practices folgt, der hilft der KI (mehr unter 5.3) dabei, die Daten besser zu finden.
Was heißt das jetzt konkret?
Der Index nutzt die ihm zur Verfügung stehenden Informationen, um einen Sucherfolg zu ermöglichen (wie gesagt, technisch mehr unter 5.3). Und eine verfügbare Information ist auch der Dateiname und der Speicherort – damit meine ich „liegt es in meinem Onedrive Root oder liegt es in einem passenden SharePoint bzw. Teamskanal“.
Fangen wir mit dem Namen an: wenn ich 100te Dateien „Angebot.docx“ habe, dann ist das nicht hilfreich!
Wenn ich aber Dateien der Form „2023-10-31-Angebot-Projekt-ABC.docx“ in dem Teams „Contoso“ im Kanal „Innovationen“ habe, dann hilft das dem Index ungemein die Datei in dem richtigen Kontext zu verstehen!
Update Oktober 2024:
Mittlerweile gibt es in SharePoint und OneDrive ein Feature, welches automatisiert dabei unterstützen kann die redundanten Dateiversionen zu reduzieren: Plan version storage for document libraries – SharePoint in Microsoft 365 | Microsoft Learn
5.2 Metatagging
Was (Meta)tags sind, wissen vermutlich die meisten, noch mal kurz: das sind Schlagworte, die zum Beispiel an Blogposts wie diesen gehängt sind, um den Blogpost besser zu klassifizieren und finden zu können. Genau das ist auch mit Dateien – sowohl an den Dateien selbst als auch z.B. in SharePoint möglich.
Schon mal gemacht? Ok, damit befindest du dich in bester Gesellschaft, denn die meisten wissen gar nicht, dass das sehr einfach mit (Office) Dateien möglich ist!
Sidenote: in NTFS ist so etwas über die sogenannten Streams möglich und wird u.a. vom IE/Edge genutzt, um das so genannte „Mark of the Web“ an Dateien dranzuhängen, welches dann wiederum auch für Security Mechanismen genutzt werden kann – Stichwort: „woher kommt die Datei und was darf damit gemacht werden“.
Aber zurück zum Thema Metatagging mit Office Dateien: unter „Datei->Informationen“ gibt es in den Office Apps die Möglichkeit Tags zu setzen, als Beispiel für das Dokument, in dem ich den Blogpost vorschreibe:
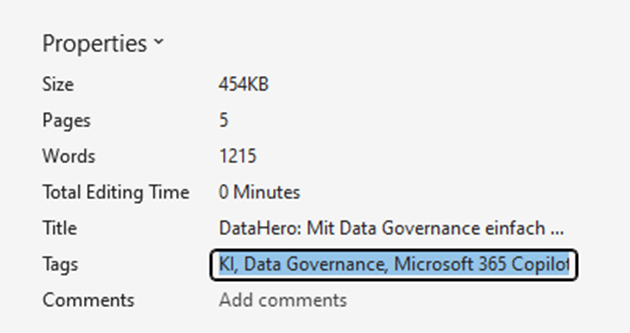
Das sieht auf den ersten Blick nach „Arbeit“ aus!
„Ich muss mir neben dem eigentlichen Schreiben auch noch Gedanken über Metatags machen, hilft mir eh nicht, also lasse ich es!“
Jede Userin, immer
…wird der erste Reflex der meisten Userinnen sein. ABER – zum einen ist es unsere Aufgabe es allen Menschen mitzuteilen, dass es ihnen sehr wohl hilft – zum anderen ist es überhaupt keine Arbeit, wenn ich mich von KI unterstützen lasse:
(Das „Bitte“ könnte auch weggelassen werden, die KI nimmt es uns (noch ) nicht übel, wenn wir unfreundlich sind, oft kann das Vermenschlichen und Freundlich sein auch zu schlechteren Ergebnissen führen!)
Und so ist es ein einfaches copy&paste, welches in wenigen Sekunden genau diese Unterstützung liefert.
Kleiner Wehrmutstropfen: bis jetzt macht die KI/Copilot das leider noch nicht von alleine – es muss ja noch Room for improvements geben!
5.3 Semantische Indizierung / Semantic Index / Vector Search
Auf dieses Thema könnten wir sicher mehrere tief technische Posts verwenden. Keine Angst, werde ich nicht machen, würde auch zu weit führen.
Ich möchte insbesondere auf ein fantastisches Video von Microsoft Mechanics verweisen, welches sehr schön plastisch erklärt, wie diese neue Form der Indizierung funktioniert:
Kurz zusammengefasst: basierend auf den (Meta) Informationen wird ein Vektor (mathematisch ein gerichteter Pfeil mit einem Ursprung, einer Richtung X-Y-Z [bei 3 Dimensionen] und einer Länge) erstellt. Wenn ich nun nach einer bestimmten Information suche, dann werden mögliche Treffer, also deren Vektoren, verglichen und vor allem der Abstand der jeweiligen Vektoren zueinander berechnet („Mist, hätte ich doch mal in der Schule aufgepasst…“ ). Muss man zum Glück nicht selber machen, übernimmt die Suche (=> Azure Cognitive Search – Cloud Search Service | Microsoft Azure) für uns!
Über diesen Mechanismus lassen sich durch die Anwendung der o.g. Metainformationen viel genauere Ergebnisse erzielen, die deutlich über klassische Keyword-Search hinausgehen, weil zum Beispiel eine Datei, in der nur von „KI“ aber nicht von „Copilot“ die Rede ist, trotzdem eine deutliche Nähe des Vektors zu einer Datei mit „Copilot“ aufweist und daher dann auch höher gerankt und zugeordnet wird.
Das verändert nicht nur unsere „Vorbereitungsmaßnahmen“ (vgl. oben), sondern auch die Art und Weise, wie wir zukünftig mit oder ohne KI suchen!
Ich muss nämlich nicht mehr „Copilot KI AI chatgpt“ in die Suche eingeben, sondern in Zukunft reicht „KI“ und die anderen Ergebnisse sollten dann entsprechend auch auftauchen!
Fazit
Ordnung ist das halbe Leben (Arbeit die andere Hälfte)
meine Mutter, insb. wenn mein Zimmer aufzuräumen war! 😇
hat meine Mutter früher immer gesagt – und spätestens jetzt muss ich ihr Recht geben, denn wenn die von mir oben aufgezeigten Dinge ordentlich und ja – auch mit etwas Aufwand/Arbeit – umgesetzt werden, dann erleichtert es das Leben ungemein und wenn man dann die Benefits am eigenen Leib spürt, dann wird es zunehmend auch weniger Arbeit und mehr Natürlichkeit werden! Neben den hier aufgezeigten Vorteilen hilft es auch bei Security, Insider Risk, etc. – aber das ist ein Thema für einen späteren Blogpost!
UPDATE: Mittlerweile ist die Microsoft Ignite 2023 vorüber und es gab mindestens die beiden folgenden Sessions zu dem Thema, die auch die Bedeutung von Microsoft Purview u.a. in Demos klar hervorheben:
- Getting your enterprise ready for Microsoft 365 Copilot | BRK257HG
- Learn Live: Prepare for, implement, and secure Microsoft 365 Copilot
- Und das schon ältere: How to get ready for Microsoft 365 Copilot – YouTube
UPDATE2: Verpasst auch nicht den neuen Artikel als Anschluss zu diesem über Halluzinationen von künstlicher Intelligenz: Wie sie entstehen und was wir dagegen tun können
UPDATE3: Die Zeit vergeht und die Ignite 2024 ist mittlerweile auch vorüber und bringt uns folgende tolle Sessions:
- Follow the Prompt! Tracking and Managing Copilot prompts at hyperscale
- Prepare your data for Microsoft Copilot with new tools
- Secure and govern data in Microsoft 365 Copilot and beyond
- Wie immer gilt: ich schließe explizit niemanden aus und beziehe in jegliches Genus alle anderen mit ein – für die Inklusion und die Lesbarkeit verwende ich immer nur genau ein Genus! ↩︎
Kommentare
3 Antworten zu „DataHero: Mit Data Governance einfach mal die KI-Welt retten“
[…] Stephanus neuer Blogpost: DataHero: Mit Data Governance einfach mal die KI-Welt retten – Stephanus (st-s.info) […]
[…] Die Qualität der zugeführten Daten immer einem möglichst hohen Grad entspricht. Dazu ist es zwingend notwendig, dass die Daten einer entsprechenden Governance unterliegen und diese auch eingehalten wird, vgl. DataHero: Mit Data Governance einfach mal die KI-Welt retten […]
[…] Daher mein Aufruf: jeder (!) kümmert sich jetzt um seine Data Governance und nutzt dann gelassen die neue KI Welt zum Wohle aller!Siehe dazu auch meinen Blogbeitrag: DataHero: Mit Data Governance einfach mal die KI-Welt retten […]