Ich habe schon in verschiedenen anderen Blogposts das Thema Zero-Trust (ZT) aufgegriffen (Jurassic Park, Ransomware, BYOD,…).
In diesem Post möchte ich herausarbeiten was ZT für die Infrastruktur bedeutet und wie diese schrittweise transformiert werden sollte.
FYI: Hier der zweite Teil und wie durch entsprechendes Vorgehen die digitale Transformation getrieben werden kann: Wie Cybersecurity dazu beitragen kann, die digitale Transformation voranzutreiben
Inhaltsverzeichnis:
Bevor ich mit der eigentlichen Story loslege, starten wir vorher einmal kurz mit den drei Grundprinzipien von ZT und wie man sich Zero-Trust bildlich vorstellen kann:
Zero Trust Prinzipien
- Assume Breach
- Verify Explicitly
- Least Privilege
Das klingt etwas steif, zur Verdeutlichung hier eine Analogie in Bezug auf die on-premises Infrastruktur:

Stellen wir uns vor das lokale Intranet sei ein Swimming-Pool:
Dabei ist das Wasser das Netzwerk, die Erwachsenen könnten die Services und Server darstellen und die glücklichen Kinder ebenso glückliche Nutzer*innen.
Initial ist natürlich alles in bester Ordnung, aber was ist „wenn“?
Sprich was ist, wenn etwas sich bei eine*r User*in ändert?

{kind=link}
Tja, in dem Fall sind alle im selben Netzwerk aka Swimmingpool betroffen: alle (erreichbaren) Erwachsenen/Server und auch alle erreichbaren Kinder/User*innen.

[Ein verwegener Vergleich wäre: „Microsoft Defender = Urinator + Bademeister“- beide zeigen auf, wenn etwas schiefgegangen ist, mit dem Unterschied, dass die Microsoft Defender Komponenten „for O365“, „for Identity“ und „for Endpoint“ auch gleich Gegenmaßnahmen ergreifen können und wir dazu eben nicht noch den Bademeister als Zusatzkomponente benötigen!]
Abhilfe schafft hier vor allem eins:
mit der Idee „assume breach“ eine Segmentierung über alle möglichen Kleinstkomponenten, d.h. idealerweise User, Server/Services.
Im Bild sähe das dann so aus:

Das heißt „jeder spielt in seinem eigenen Pool“ und wenn die glücklichen Kinder dann doch auf Ideen kommen, dann sind sie nur alleine betroffen und die Auswirkungen können mit wenig Aufwand eingefangen werden – hier also wenige Liter Wasser einfach zu ersetzen, in der IT Realität bedeutet das dann, dass nur ein Client/Server/Service neu aufgebaut werden muss und nicht „alle“.
„Ohne Zero Trust ist das on-premises Netzwerk wie ein Swimmingpool mit Urinierbereich“
Stephanus
Wie kommen wir nun zu einer ZT Infrastruktur?
Schritt 1 – Ausgangssituation
Eine durchschnittliche, normale Intranetarchitektur sieht oft vereinfacht so aus:

D.h. die meisten Clients, Server und Services befinden sich im gemanagten Corp Intranet, welches über einen Breakout mit dem Internet verbunden ist.
Oft werden unmanaged Clients nicht erlaubt/geduldet, falls doch, dann oft nur mit sehr limitierten Möglichkeiten.
Sofern Cloud Services überhaupt (offiziell) genutzt werden (dürfen), werden diese klassisch über den firmeneigenen Proxy/Firewall angesteuert.
Dieses Vorgehen beherbergt gleich eine Vielzahl an Nachteilen:
- Sizing des Breakouts
- Outbound wird der komplette Netzwerkverkehr über einen/wenige Leitungen geleitet, welches entsprechende Anforderungen an die Netzkapazität und die verwendeten Koppelkomponenten stellt.
- Inbound wird der komplette Netzwerkverkehr über einen/wenige Leitungen geleitet, welches entsprechende Anforderungen an die Netzkapazität und die verwendeten Koppelkomponenten stellt.
- VPN behandele ich im nächsten Schritt.
- Alle sitzen in einem Pool, jeder erreicht jeden, incl. Ransom- und Malware
- Schnelles Eindämmen ist fast unmöglich
- Änderungen an Diensten und LOB Apps bedürfen Zeit und aufwändige Prozessen
- Skalierung und Redundanzen sind umständlich und teuer
Schritt 2 – Netzwerksegmentierung (Clients)
Der erste Schritt hier besteht darin die Clients aus der Gleichung zu entfernen und diese – ob managed oder nicht – aus dem direkten Intranet zu entfernen und idealer Weise bei Verwendung von VPN einzeln zu segmentieren:

Um diesen Schritt vollständig umzusetzen muss das Ziel sein die Verwendung von VPN auf das absolute Minimum herunterzubringen – idealerweise auf 0.
Dazu werden Services und LOB Applikationen, die heute noch on-premises laufen per Azure AD App Proxy „ins Internet“ gepublished, wobei diese nur über eine erfolgreiche (MFA) Authentication zugreifbar sind (verify explicitly).
Große Vorteile bei diesem Vorgehen sind:
- Applikationen sind ohne (Client) VPN erreichbar
- Applikationen werden auf der „My Apps“ Übersicht der User aufgeführt
- Applikationen können mittels MFA abgesichert werden, auch wenn diese keine eigenständige MFA Funktionalität und/oder veraltete Authentication Protokolle mitbringen
- Applikationen sind nur für die User tatsächlich erreichbar, die dafür vorgesehen sind (Least priviledge!)
- Es können Conditional Access Policies für den Zugriff verwendet werden
- Ggf. können Session Controls für den Zugriff verwendet werden
- Abhängig von der App bzw. der Confidentiality können auch unmanaged/BYOD Clients darauf zugreifen.
- VPN Infrastruktur ist wesentlich kleiner und viel einfacher wart- und verwaltbar
- Zugriffe sind auditierfähig nachvollziehbar – insb. für DSGVO wichtig!
Durch diesen Schritt werden die größten Angriffsflächen (User/Clients) deutlich verringert. Aber das reicht noch lange nicht!
Schritt 3 – Netzwerksegmentierung (Server/Services)
Nachdem nun die Clients an sich „kein Risiko“ mehr bedeuten muss nun das Netzwerk in verschiedene Brand- und Sicherheitsbereiche unterteilt werden:

Dazu müssen die Netzwerk Devices und Anforderungen klassifiziert werden, zum Beispiel in:
- Business Critical Segment(s)
Hoch sensitive Dienste wie typischerweise so etwas wie ERP (SAP), Forschungsapplikationen. Alles, was bei Kompromittierung den Fortbestand der Unternehmung gefährden würde - High Impact IoT/OT
Alle IoT/OT Dienste und Geräte, die bei (mutwilliger) Fehlfunktion das Leib und Leben von Menschen direkt gefährden würde, zum Beispiel autonome Fahrzeuge, Roboter, etc - Low Impact IoT/OT
Alle anderen zum reibungslosen Betrieb notwendigen Dienste und Devices, zum Beispiel Drucker, Telefone, etc. - Sonstiges, LOB Applikationen, die nicht Business kritisch sind
Alle verbleibenden, sonstigen Dienste und Server verbleiben in diesem Schritt dort, wo sie bis jetzt sind. Idealerweise sollten diese zumindest bis hierhin virtualisiert worden sein
Wenn diese Geräte und Dienste entsprechend gefunden, klassifiziert und separiert sind können für den entsprechenden Zugriff weitere Regeln und Maßnahmen (spezielle Firewalls, IDS, Monitoring, Redundanzen, etc) herbeigeführt werden.
Pro Tipp:
auch wenn ich „Drucker“ hier als Low Impact ausgewiesen habe sollten diese spätestens bei der Entsorgung bzw. der Leasing Rückgabe als High Business Impact gewertet werden, denn oftmals wird dabei die im Gerät vorhandene Festplatt vergessen, auf denen sich zumeist sehr viele, unverschlüsselte Dokumente befinden.
=> Ergo: Drucker Festplatten schreddern!
Schritt 4 – Mikrosegmentierung der Serverinfrastruktur
Last but not least muss sich noch um die verbliebenden Server & Services gekümmert werden, damit auch für diese das Risiko minimiert und die Handlungsmöglichkeiten bei Detektion von ungewollten Zugriffen/Verhalten maximiert werden:
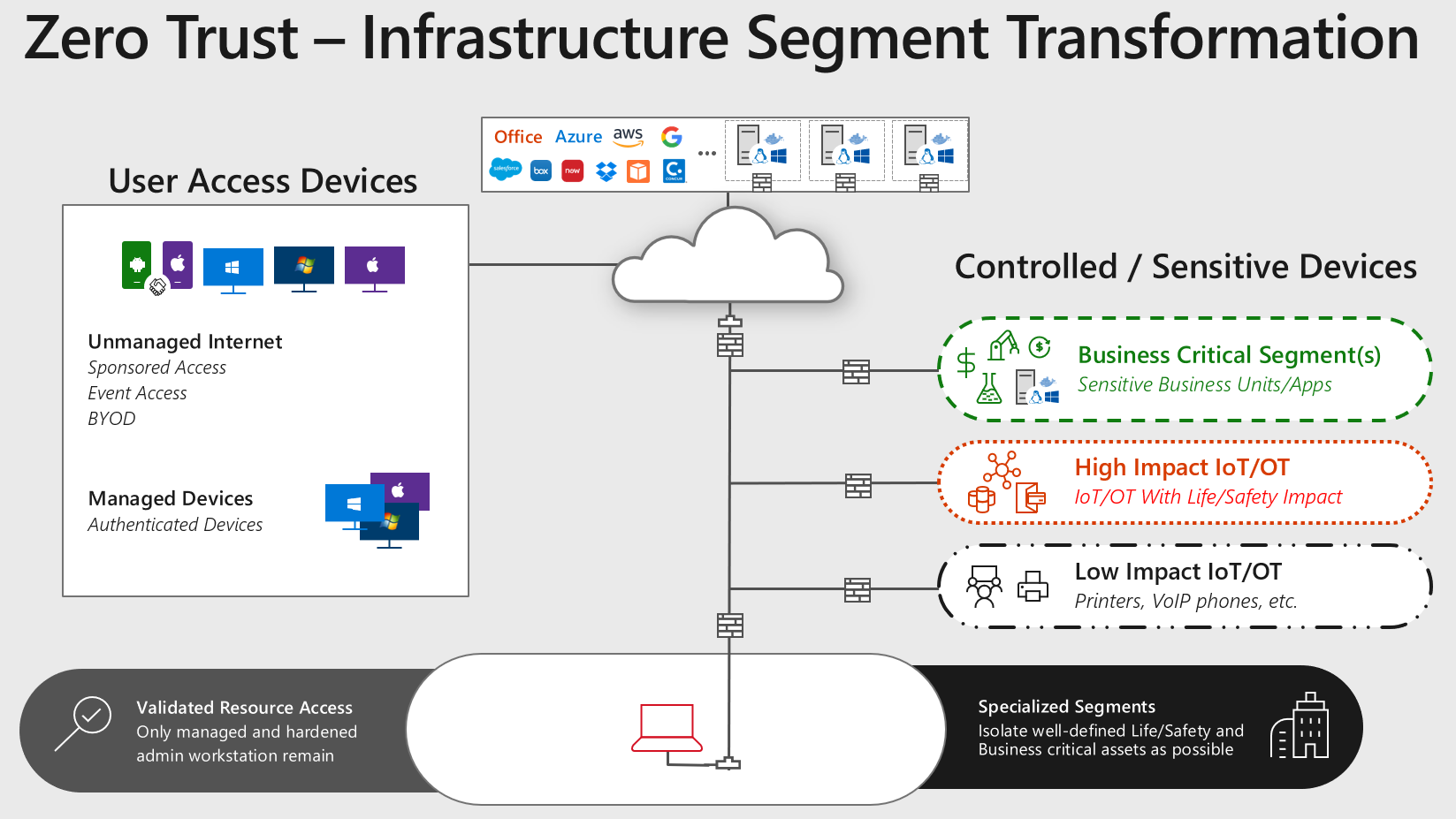
Da diese in Schritt 3 ja bereits mind. virtualisiert worden sind, ist es jetzt fast nur noch eine Fleißaufgabe diese in virtualisierte Netzwerksegmente zu überführen – und wenn das getan bzw. möglich ist, dann lassen sich diese auch in IaaS Clouds per Lift&Shift überführen – am Besten natürlich nach Microsoft Azure IaaS.
Vorteil bei diesem Vorgehen ist:
- Einfluss von erfolgreichen Angriffen auf das Mikrosegment begrenzt, Wiederherstellung des Dienstes/Segments durch:
- Backup und Restore des gesamten Services mit allen Layern durch Cloud Mechanismen sehr einfach möglich
- Performance des gesamten Services per Elastizität in der Cloud hoch- und runterfahrbar, sprich Montagmorgens volle Leistung aka „dicke Hose“ und über Nacht oder am Wochenende „Schmalhans“
- Replikation bzw. Spreizung der einzelnen Dienste über Regionen durch die Mikrosegmentarchitektur schnell, standardisiert und automatisiert möglich
- Zugriff komplett autark von der on-premises Infrastruktur,
- Authentication und Zugriff von überall möglich
- Abrechnung der Dienste nach Aufwand und Einzeldienst möglich, Stichwort „Interne Verrechnung“
Fazit
Nach erfolgreicher Transformation der kompletten IT Infrastruktur hin zu einer Zero-Trust Infrastruktur ergeben sich neben den Security Vorteilen auch noch weitere oft vernachlässigte Möglichkeiten:
- Einfacherer, direkterer und von der (veralteten?) on-premises Infrastruktur losgelöster Zugriff, Stichwort. „Working from anywhere“
- Höhere Userakzeptanz
- Bessere Skalierfähigkeit
- Robuster gegen alle möglichen ungewollten Ereignisse
- Risikoverlagerung
- Höchster Standardisierungs- und Automatisierungsgrad
- Volle Transparenz auf erbrachte IT Leistungen und damit nachvollziehbare Abrechnung
- Geringerer Aufwand bei der Verwaltung der Infrastruktur
- Abgrenzung von IT Dienstleistungen für einzelne Länder und Regionen
Tja, wenn man das so liest, dann drängt sich einem die Frage auf: warum machen es dann nicht eigentlich alle?
Gute Frage! Also los, nicht warten! Microsoft Partner helfen bei der Umstellung und bei allen weiteren Fragen!
Weiterführende Links
- Was hat Jurassic Park mit IT Security zu tun?
- Kein Mitleid mit Ransomware
- Implementing a Zero Trust security model at Microsoft
- Zero Trust Overview
- Zero Trust networking: Sharing lessons for leaders
- Zero Trust Blog – Microsoft Security
- Embrace Zero Trust with Azure Active Directory – Learn | Microsoft Docs
- How Microsoft does Zero Trust – Microsoft Tech Community
Kommentare
5 Kommentare zu „Zero Trust und was das für die Infrastruktur bedeutet“
[…] Klassischer Weise kommt Ransomware über Emailattachments auf die erste betroffene Maschine. Danach gibt es typische „Standard-Verteil- und Verbreitungsmechanismen“ über das angeschlossene Netzwerk (vgl. „Zero Trust und was das für die Infrastruktur bedeutet„). […]
[…] eure Identitäten!Am besten gleich auf den Weg zu Zero-Trust machen!Gerne dazu auch zuerst die „Low hanging Fruits für 98% Sicherheit“ […]
[…] Zero Trust und was das für die Infrastruktur bedeutet […]
[…] meinem Artikel über Zero Trust und was das für die Infrastruktur bedeutet habe ich bereits beleuchtet, welche Mittel genutzt werden können und sollten, um die ersten […]
[…] eine Mikrosegmentierung für Server/Services notwendig ist und umgesetzt werden kann, habe ich in Zero Trust und was das für die Infrastruktur bedeutet beschrieben und warum ein solches Vorgehen Kosten sparen und die eigene digitale Transformation und […]